在近年来的科技浪潮中,生成式AI模型已然成为了一个备受瞩目的热点,尤其是伴随ChatGPT等大型语言模型(LLM)的崛起,推动了技术的发展与应用的普及。这些生成式AI模型不仅可以理解自然语言输入,还能为用户提供贴切的输出,导致了其它生成式技术的迅速崛起。特别是像DALL-E和Midjourney这样的图像生成产品,它们的流行正是得益于一种被称为“扩散模型”(Diffusion Model)的技术。
本文将深入探讨扩散模型的原理与机制,力求揭示这一核心技术背后的奥秘,以及它如何成为现代图像生成的支柱。
扩散模型简介
扩散模型属于生成式模型的一类,旨在根据预先训练的数据生成新数据,尤其是在图像生成方面表现突出。其工作流程与传统的图像生成方法有显著不同,扩散模型在生成图像时采用了“添加噪声与去噪”的双重过程。具体而言,这个模型对图像引入噪声,使其逐渐退化成随机噪声图像,然后训练模型再逆向操作,以此从噪声数据中生成清晰的图像。
源起与演进
扩散模型的理论基础可以追溯到2015年,Sohl-Dickstein等人的论文《使用非平衡热力学的深度无监督学习》中首次提出了这种概念。该论文提出了“受控正向扩散”的过程,强调将数据逐步转变为噪声,然后再逆变以重构原始数据的可能性。2020年,Ho等人的《去噪扩散概率模型》显著提升了模型的生成能力,使其在图像生成质量上超越了生成式对抗网络(GAN),为现代扩散框架奠定了基础。
正向与反向过程
扩散模型的生成过程由两个核心部分组成:正向过程和反向过程。
正向过程
正向过程是将原始图像逐步变为噪声的步骤。具体流程如下:
1. 从数据集中选取一张图像开始;
2. 向该图像添加一点噪声;
3. 重复添加噪声的操作,经过数百或数千次后,原始图像将完全变为随机噪声图像。
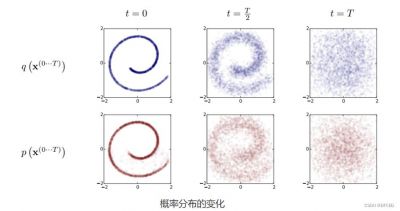
这个过程被数学建模为马尔可夫链结构,每一次的噪声变化仅依赖于前一步。这种逐渐添加噪声的方式相比一次性转变,更能够帮助模型学习如何逆向去噪,逐步从无序中恢复图像细节。
为了保证每一步的噪声添加合适,模型使用了噪声调度的方法。这意味着在整个过程中噪声的引入速度和方式可以变化,例如使用线性或余弦调度,使模型能更好地捕捉与保留有用的图片特征。
反向过程
反向过程则是将噪声逐步转换为清晰的图像。这一过程与正向过程相反,从完全随机的噪声图像开始,通过训练好的神经网络,模型迭代地去除噪声,使得图像逐渐清晰化。
反向过程需要经过预先训练的模型,在每一步中使用当前的噪声图像和时间信息作为输入,利用在训练过程中学习到的参数进行反向预测。卷积神经网络(例如U-Net)的架构常被用作反向生成器,模型会根据每一步的噪声情况和时间步长来调整生成,确保生成结果的稳定性和质量。
文本调节机制
在一些文本转图像的应用(如DALL-E和Midjourney)中,扩散模型可以通过自然语言提示进行调节,这一过程被称为文本调节。文本调节利用如CLIP预训练模型,将文本提示转换为向量嵌入,然后通过交叉注意力机制将文本与生成的图像状态对齐。每一步生成图像时,模型都能聚焦于文本说明的特定部分,使生成的效果符合用户的期望。
DALL-E与Midjourney的比较
尽管DALL-E与Midjourney都建立在扩散模型的基础之上,但它们在技术实现上存在差异。DALL-E运用基于CLIP的向量嵌入,而Midjourney则拥有自己独特的扩散架构,强调高真实感和细致的图像风格。在提示处理方面,DALL-E能更好地应对长提示的生成,而Midjourney则在简单提示方面表现出色。
扩散模型的引入不仅推动了生成式AI的发展,还为现代文本至图像生成系统提供了强大的技术支持。通过正向与反向过程的结合,扩散模型能够从随机噪声中不断精炼生成高质量的图像。同时,借助自然语言的调节机制,用户可以轻松控制生成结果。随着技术的进步,扩散模型的应用前景将持续扩展,在更多领域展现出其潜力。