近年来,存算融合(Compute In Memory, CIM)这一概念迅速崛起,成为计算领域的一大热潮。为何会提出存算融合?这源于传统冯·诺依曼架构的不足,尤其是在当前数据爆炸增长和人工智能(AI)飞速发展的背景下,存储和计算的分离设计已经无法满足高效处理海量数据的需求。
冯·诺依曼架构作为计算机设计的基础,自计算机诞生以来一直在应用。在该架构中,存储和计算是独立的模块,数据存储与运算的过程需要频繁的数据传输。这就如同烹饪中的配菜与炒菜,配菜的效率直接影响到上菜的速度。若配菜没跟上,炒菜师傅就得耐心等待,从而影响整体的工作效率。
随著互联网和AI的崛起,数据产生量以指数级增长,这一传统架构的局限开始显露。计算芯片的性能不断提升,但存储设备与计算单元之间的数据传输速率却未能同步提升,导致“存储墙”和“能量墙”两大瓶颈现象愈发明显。存储墙是指存储器和处理器之间的数据传输速度无法满足处理器的高计算能力,而能量墙则意味着在数据传输过程中,消耗大量能量降低了整体系统效率。
近年来,随着高带宽内存(HBM)等新型存储技术的出现,业界在尝试解决这两大问题。HBM技术通过先进的3D封装,缩短了存储单元和计算单元之间的距离,在一定程度上提高了数据传输效率,同时降低了能耗。这依然无法根本解决存储和计算之间的壁垒。因此,更为彻底的解决方案——存算融合应运而生。
存算融合的基本思路是将存储和计算集成在一起,让数据在存储的同时进行计算,反之亦然,从而减少数据的搬运次数。这一理念可以追溯到人类大脑的结构,神经元既负责存储信息,也同时进行处理,这种结构使得人脑在处理复杂任务时表现出高效性和低能耗特性。
存算融合的研究虽然早在1969年便已提出,但由于技术限制,初期只是停留在理论阶段。进入21世纪后,随着半导体技术的不断成熟,存算融合的研究逐渐取得了重要进展。例如,2010年,惠普实验室的研究团队首次利用忆阻器实现了简单逻辑运算;2016年,加州大学的研究则展示了如何使用阻变存储器构建存算融合的深度学习神经网络PRIME,使得计算速度提高了50倍,并大幅降低功耗。
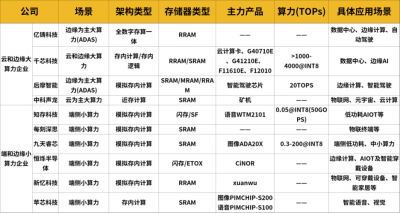
随着AI技术的快速发展,算力需求急剧上升,存算融合技术开始得到普遍关注。行业内各大企业和创业公司纷纷参与到这项技术的研发之中,推动存算融合的快速发展。例如,国内外的多家初创企业如苹芯科技、后摩智能、Mythic等,正致力于将存算融合的理念落到实处。
在技术分类上,存算融合主要可分为近存计算、存内处理和存内计算三类。近存计算通过封装和板卡集成等手段将存储和计算单元靠得更近,减少数据交互延迟,以提高整体计算效率。存内处理则是在内存芯片中集成基本的计算能力,进一步缩短存储和计算的距离。而存内计算是最彻底的实现,将存储单元和计算单元设计为一体,真正实现计算和存储的无缝融合,特别适用于深度学习等高强度计算任务。
存算融合的实现也有多种存储技术支持,包括易失性和非易失性存储器。尤其是忆阻器(RRAM)等新型存储技术被广泛关注,它们在存储的同时也能进行运算,具有较高的能效比。
尽管存算融合技术前景广阔,但其实际应用仍面临诸多挑战。在技术方面,对半导体材料和电路设计的要求更高,需要更多的创新。生态系统的建设仍然不完善,缺乏成熟的设计工具和应用软件支持。市场需求的不确定性以及传统架构的强大依旧是存算融合技术广泛应用的障碍。
尽管如此,随着技术的不断成熟和厂商的不懈努力,存算融合将在未来实现更广泛的应用。根据市场调研数据显示,存算融合技术市场预计在未来几年有着极大的增长潜力,保持较高年复合增长率。
存算融合的出现不仅是对冯·诺依曼架构的一次突破,更是在处理信息效率和能耗优化方面的一次重大革新,预示着高效计算新时代的到来。未来,我们有理由相信,存算融合将会在众多应用领域开辟出新的可能性,引领计算技术向更高的领域迈进。