在人工智能(AI)飞速发展的背景下,大模型已经成为业界关注的焦点。这些模型不仅能进行自然语言对话、代码编写和图像生成,还蕴含了更为复杂庞大的技术体系,包括大规模、质量高且多样化的数据,先进的模型架构,训练策略,推理部署系统及资源调度等支持能力。科学评测机制也是不可或缺的部分。大模型并非简单的应用,而是一个由模型、数据、系统和评测等元素共同构成的“技术生态”。
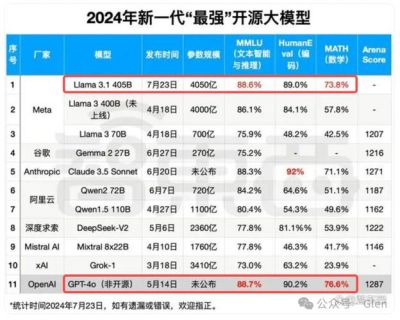
随着商业化路径中的闭源技术壁垒逐渐显现,开源大模型的崛起为AI技术的普及提供了新的动力。面对众多开源AI模型技术的层出不穷,选择合适的技术方案变得尤为重要。在此背景下,CSDN联合多家机构于2025全球机器学习技术大会(ML-Summit 2025)上发布了《AI大模型技术体系综合开源影响力榜单》,对全球各大开源大模型技术体系进行了综合评估,目的是为行业提供参考,推动开源创新不断向前发展。
这份榜单独特之处在于,它不仅关注单一的大模型,还将目光投向整个大模型技术生态,从模型、数据、系统和评测四个关键环节进行全景式评估。之所以选取这四个维度作为核心,是因为它们共同构成了大模型发展的基本支撑。
在模型维度方面,所评估的模型种类越丰富,支持的模态越多,覆盖的应用场景则越广,进而推动社区的技术创新加速。模型的表现往往取决于数据的质量与多样性,基于此,评估机构在开源数据和数据处理技术的覆盖广度、数量和实际应用情况等方面进行考量,进而直观反映其在大模型生态中构建基础设施的能力。
系统维度则关注开源系统的适应能力,尤其是对不同芯片的支持力度,包括国产芯片,能够提高模型训练和部署的效率。开源评测工具和排行榜的完善程度,也能帮助研究者和开发者科学地进行比较与快速迭代,不断提升模型的可靠性和实际应用价值。这四个维度密切相关,缺一不可,因此榜单构建建立在模型、数据、系统和评测的框架下,设置了53项核心评估指标。
本次榜单的数据采集涉及全球17个开源,包括Hugging Face、ModelScope、GitHub和GitCode等,分析了11673个链接中的多种指标数据,覆盖了全球具有代表性的模型机构、研究团队和发布的公开资料。为了确保评估结果的科学性和可比性,榜单制定了明确的统计方法和筛选标准。这些标准涵盖了数据、模型、系统和评测的多个层面。
在榜单的各类评估中,Meta以其在模型和系统两大维度的深厚积累,跻身总榜首。其主导发布的LLaMA系列模型已经成为全球开源语言模型的基石,极大丰富了开源生态。Google紧随其后,凭借轻量化大模型理念与完善工具链,展现了良好的性能和开放性。
在国内,智源人工智能研究院(BAAI)在数据、模型和评测等多个维度均表现出色,特别是在系统层面的突出优势值得关注。阿里巴巴在开源影响力榜单中排名第四,通义千问(Qwen)系列模型的持续更新表现优异。Ai2因其发布的C4数据集在数据维度中拔得头筹,成为广泛使用的资源之一。
在榜单中,DeepSeek表现尤其引人注目,其多个新发布的模型在性能上取得了不俗成绩,并在社区中获得了迅速反响,成功跻身全球第九名。OpenAI则排名第十,尽管其核心模型并未全面开源,仍然是行业中具有影响力的力量。
,CSDN将继续致力于推动评估体系的行业标准化,起草《人工智能大模型技术体系开源影响力评估方法》白皮书,并计划于5月中旬正式对外发布。同时,随着多模态技术的普及,模型的能力边界不断扩展,评测标准趋于精细,当前的评估框架也将持续进行优化,确保榜单的公平性、合理性与前瞻性。
本次评选所依据的“大模型技术体系开源影响力评估框架”已在GitHub和GitCode上开源,欢迎广大参与者积极参与,共同推动中国开源大模型生态的发展。