近日,谷歌研究院正式发布了其全新“Titans”系列模型架构,标志着自然语言处理领域的一次重大技术进步。这一系列模型的核心创新在于“仿生设计”,致力于提升现有人工智能在处理长序列数据时的能力,从而克服传统模型在上下文窗口方面的限制。相关论文已经在arXiv上发布,谷歌也计划在未来将Titans技术进行开源,为研究人员和开发者提供新的工具。
当前,业界普遍采用的Transformer模型架构虽然在多种应用场景中表现出色,但其在上下文处理上的局限性常常成为制约。一般而言,Transformer模型的上下文窗口长度大多处于几千到几万个Token之间,这对于许多需要深度语义理解的任务,如长篇文章的分析、多轮对话的上下文跟踪,以及大规模上下文记忆的应用,往往显得力不从心。这种局限不仅导致了语义的断裂,也降低了信息的准确性,极大影响了模型在复杂任务下的表现。
为了解决这个问题,谷歌在Titans的设计中引入了深度神经长期记忆模块(Neural Long-Term Memory Module),这个模块的灵感源自人类的记忆系统,通过将短期记忆的快速反应与长期记忆的持久特性相结合,进一步通过注意力机制来聚焦于当前的上下文信息,显著提升了处理长序列的能力。
Titans系列模型拥有三种不同的架构变体,分别为Memory as a Context(MAC)、Memory as a Gate(MAG)和Memory as a Layer(MAL)。这些变体能够根据不同的任务要求灵活整合短期与长期记忆,满足多样化的应用需求。
具体MAC架构将长期记忆视作上下文的一部分,允许注意力机制在处理当前数据时,动态地结合历史信息。这种设计尤其适合于需要详细历史背景和上下文关联的复杂任务,如法律文书的解析和文学作品的分析等。另一方面,MAG架构则能够根据具体任务的需求,适时调整实时数据与历史信息的重要性,这使得模型能够更好地聚焦于当下最相关的信息,优化实时响应和决策过程。
MAL架构则将记忆模块整合到深度网络的一层中。从模型设计的角度来看,这一变体通过固定压缩用户的历史记录和当前输入的上下文信息,从而在处理时提高了效率。不过,相较于MAC和MAG,MAL在输出效果上稍显不足。
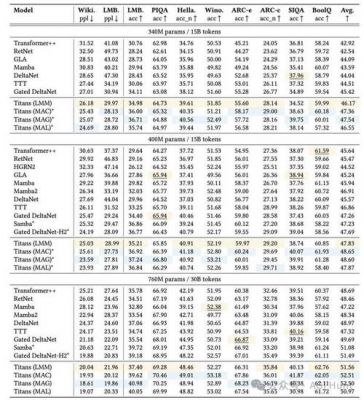
谷歌认为,Titans系列模型在长序列处理任务上的性能显著优于现有的模型。不论是语言建模还是时间序列预测,Titans在准确性和效率方面都表现出了显著的“压倒性优势”。在某些具体场景下,Titans甚至能够超越如GPT-4等参数数量多达数十倍的模型,这一点引起了行业内的广泛关注。
可以预见,此次谷歌的Titans系列模型架构不仅将在自然语言处理技术上带来重大突破,还将对人工智能的应用场景拓展产生深远影响。随着模型的开源,研究者们将能够进一步探讨和优化这一架构,甚至将其应用于不同的领域,如客户服务、医疗诊断、金融分析等,为相关行业带来更为精准和高效的解决方案。
谷歌的Titans系列不仅是技术上的一次重要创新,更是人工智能长期以来在记忆能力和信息处理方面突破的真正体现。而随着技术的不断演进,我们期待这一系列模型在未来能够推动更多领域的创新与发展。